(For the impatient : Example videos at end of post)
I wanted to try and stream video to my Apple //c since a while, but so far, I was unable to do so because I hadn’t found a good way. I would have to stream it through the serial port, as the Apple IIc has no expansion slots, so the goal was to squeeze a representation of enough frames per second in less than 1920 bytes per second, at 19200bps. This was unattainable. But I recently managed to reach a good, stable 115200bps on the serial link, and at 11.52 kB/s, the goal started to look less impossible to reach.
Let’s remember the basics about the HGR (High resolution GRaphics) monochrome mode of the Apple II: it is 280×192 pixels in monochrome mode, with each byte representing 7 pixels. The first bit of each byte is useless in monochrome mode, and the rest of the bits represent one pixel each.
The total size of an “HGR page” if 8 kilobytes, and there are two of them, which can be toggled extremely fast, but not written to extremely fast. For a good video rendering, using both pages is much better, otherwise we’d have to write on the currently displayed page, and that is slow enough to be visibly artifacting. Writing a full HGR page over serial would require about two thirds of a second, absolutely too much to reach an acceptable amount of frames.
So the requirements are: A) do double-buffering, and B) figure a way to send the least amount of data necessary.
I already have code that converts an arbitrary image to a monochrome 280×192 pixels version of it. But we have to remember the HGR page memory is not linear. The first line is stored in memory at $2000-$2028, but $2028-$2050 is line 64, etc. These complications mean that sending “pixel X,Y changed to a new value V” and have the Apple II compute the destination address would be much too slow. Fortunately, I also already have code that orders the pixels of a 1bit 280×192 image in the same way that the HGR memory is laid out, and I can use it to send single images to the Apple II in a very simple way:
sender: serial_write(hgr_buffer, 0x2000);
receiver: serial_read(0x2000, 0x2000);Using ffmpeg, it is rather simple (thanks to the examples in ffmpeg/doc/examples/!) to hook these pieces of code and generate an HGR version of each frame of a given video clip. The only remaining thing is to find the different bytes across two images, which is also trivial:
for (i = 0; i < 0x2000; i++) {
if (previous_hgr_buffer[i] != hgr_buffer[i]) {
/* This byte is different and we have to send it */
}
}Of course, to do double-buffering, we have to:
- send the full first frame to HGR page 1, have the Apple II display it, and remember what it contains
- send the full second frame to HGR page 2, have the Apple II display it, and remember what it contains
- compute the differences between the first and third frame, write them to HGR page 1 while page 2 is displayed, then display page 1.
- compute the differences between the second and fourth frame, and write them to HGR page 2 while page 1 is displayed, then display page 2,
- etc
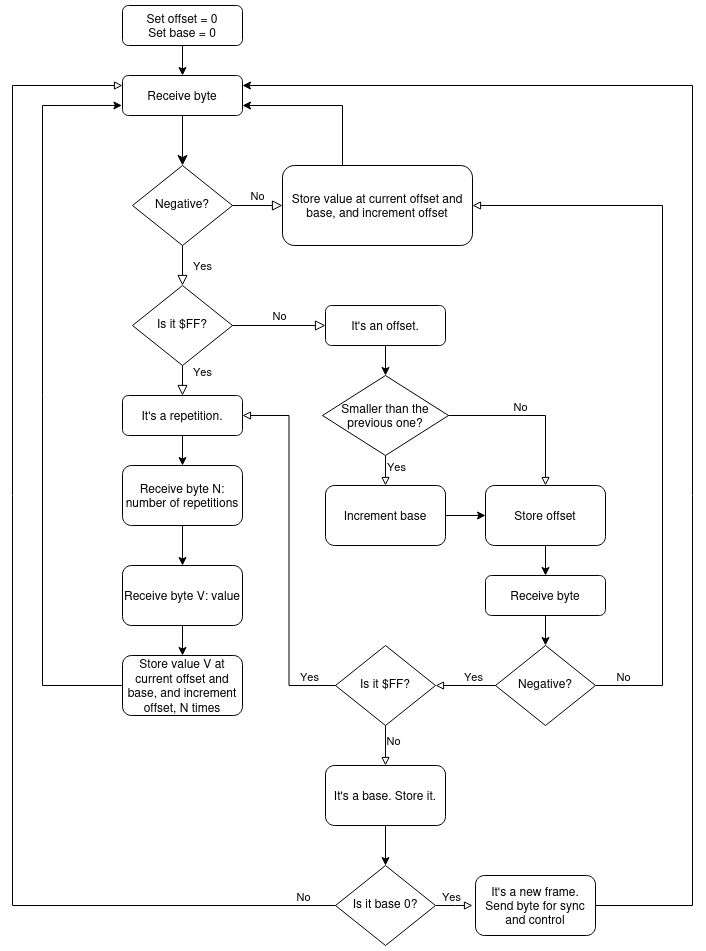
Now for the hardest thing: minimizing the representation of the differences. To do this, I have taken advantage of the fact that in monochrome mode, the high bit of each byte in HGR memory is unused. This means that on the client side, I can use this sign bit to distinguish between data bytes and control bytes. Control bytes will be used to instruct the Apple II where to store the next data byte(s).
The obvious control bytes would be to send the memory address of each byte, but that would mean I would need to send three bytes for each data byte. Instead, I have “split” the HGR pages into 65 parts, which I call “bases”, of 126 pixels each. Both server and client pre-compute a table of these “bases”.
So base 0 offset 0 is $2000, the first byte of the HGR page, representing 7 pixels; base 0 offset $26 is $2026, the first 7 pixels of line 64; base 64 offset 40 is $3FA8, the start of line 127, etc.
The stream server and the client have an understanding that they will start a frame at base 0 offset 0. After this, an example of the the algorithm is the following:
- Server sends an offset with bit 7 set.
- client recognizes a negative number, and updates its offset in the current “base”. If the new offset is smaller than the previous one, the client makes the assumption that it must update its base to the next one.
- The server is aware that the client makes this assumption, so will not send a new base if, for example, byte 120 of base 2 changed, and byte 5 of base 3 changed: following the new offset “5”, it will send the new value of the byte. But if no bytes changed in base 3 and the change following skips at least one base, it will have to send the new base to the client.
- To address that, the client checks whether the byte following a new offset is also negative. If it is, it is understood to be a new base, and it updates its pointer accordingly.
- When the client receives a positive byte, it stores it at its current (base, offset) position, and increments offset by one. That allows the server to skip sending an offset for each changed byte if multiple consecutive bytes changed: if multiple positive bytes are received, they are stored in sequence.
Experiments showed that the above algorithm could be a bit optimized if multiple consecutive bytes change to the same value. In this case, it is faster to tell the client “store value V N times” than to send N times the same value V. This optimisation requires a new type of “control byte”, used by the server to tell the client about this repetition. This control byte is $FF, a number that is both an invalid data value (as they are positive), and invalid base number (as they have a 0-66 range) and an invalid offset number (as they have a 0-126 range).
So, when the server finds a different byte, it will continue scanning differences, and if multiple consecutive bytes changed and have the same value, it will send a repetition marker ($FF), the number of repetitions, and the value. This will only be done if the number of repetitions is three or more (otherwise, it’s faster to send the same value twice), and only for a maximum of seven repetitions (otherwise, the Apple II will still be storing the value and incrementing its offset when the next byte will arrive, because writing a byte, incrementing an offset, and counting how many times we did it takes 11 cycles, and at 115200bps, a new byte arrives about every 86-90 cycles).
Finally, the synchronisation. Even optimised, there are situations where transferring the differences between two frames will take too much time (at 24 fps, we have 41.6 milliseconds per frame), like on scene changes for example. So, at each new frame (denoted by sending base 0 offset 0 unconditionally), the client will send one byte back to the server. This byte has two uses: synchronisation, and control. If the user pressed space, the stream will be paused. If the user pressed Escape, the stream will stop. Upon receiving that byte, the server will compute how much time was needed to transfer the frame’s differences, and sleep the appropriate amount of time if it took less than 41.6ms, or skip two frames (one per page) if the client is late by more than one frame.
In the end, this is the final client algorithm. It is probably not the best one could do – I’m not very good at that – but it has two advantages: minimizing the “useless” bytes, and doing almost everything as 8-bit – the only thing requiring a 16-bit word manipulation is the base update.
The implementation is available here, and the corresponding server part there.
Sadly, this level of “compression” is not enough to reach 24fps in full-screen mode. Also, even though my preferred choice of dithering is an error-diffusion algorithm which gives better results, error-diffusion causes almost all frames to be almost 100% different than the previous one, which is an enormous performance killer. So for my video streaming, I dither frames using ordered dithering. It gives the distinctive “crosshatch” patterns, but has the advantage that only the moving parts of the images change. (This is a good article on the various methods of dithering an image: https://tannerhelland.com/2012/12/28/dithering-eleven-algorithms-source-code.html).
With a 1MHz CPU and 115200bps serial link, this achieves approximately 7-8 fps in the fullscreen 280×192 resolution; 14-15 fps at 210×144, and 22 fps at 140×96. I have chosen to configure my server to send 140×96 frames and have a more fluid result.
Of course, I have tested this with Touhou’s Bad Apple video, as everyone interested in doing video on old crappy machines do, so here is the result:
It goes without saying, as I didn’t mention a word of it in this whole article, that this describes streaming video only, without sound. Since this implementation, I have extended the thing and can now play video+sound; See Wozamp for more details, and this video:
Other implementations include:
- Apple II, 1MHz, fullscreen lo-res without sound
- Texas Instruments TI 84 Plus, fullscreen with sound
- Apple II, 1MHz, fullscreen with sound, but not real-time
- Apple II, 1MHz, from floppy, not fullscreen, no sound
- Apple II, 1MHz, from CFFA3000, fullscreen no sound (by Kris Kennaway, whose II-vision player does arbitrary videos with sound but requires an Uthernet card)
- C64, 1MHz, from floppy, fullscreen with sound, but isn’t an arbitrary video player
- NES, fullscreen, with sound, not an arbitrary video player
- Amiga, fullscreen with sound
- Atari 2600, fullscreen, with sound
- Amiga 1200, fullscreen 30 fps with sound (this machine is powerful)
- Powerbook 100, fullscreen, with sound (powerfuuuul)
This last one is by Fred Stark, who also makes old 16-bit machines do unnatural things, as his full-screen, with-sound, video player MacFlim can play arbitrary videos. He’s currently busy doing a full-screen, 2-bit video player for the NeXT – here’s my version of the Matrix’s rooftop fight scene: no sound, less pixels, but more frames per seconds.